Concepts
Introduction to the API structure and data model
We’ve created a simple guide to API concepts, data model and usage, to help you build your video workflows on MK.IO.
If you are an existing AMS users, this should help you on your transition journey to MK.IOand aligning with our implementation outlined in the migration guide.
Let’s explore the API
The API is conceptually broken into four parts: Inputs, Assets, Streaming Locators, and Streaming Endpoints.

4 building blocks of the API
Input
Inputs are ways of getting content into the system.
- Content comes in and is transformed into an Asset.
- Static content is pitched to blob storage and transformed using a job.
- Live content is ingested (Live Event) and a time-shift buffer is defined using live output.
Storage
Assets are where content is stored on Blob storage and are decoupled from inputs for use at a later date.
Content protection and rewrites
Streaming locators connect DRM and filters to the asset for a dynamic packager (JITP) to process. Streaming locators are for DRM and manifest rewrites; you can have several per asset.
Publishing
Streaming Endpoints define a domain name for content and provide an option for configuring front door and CDN for the user: Streaming Endpoints are for scaling output and integrating with CDN.
Every locator is available at every endpoint.
Data Model
Everything within MK.IO revolves around an Asset -> Inputs, either file-based or live are treated as assets on the output side.
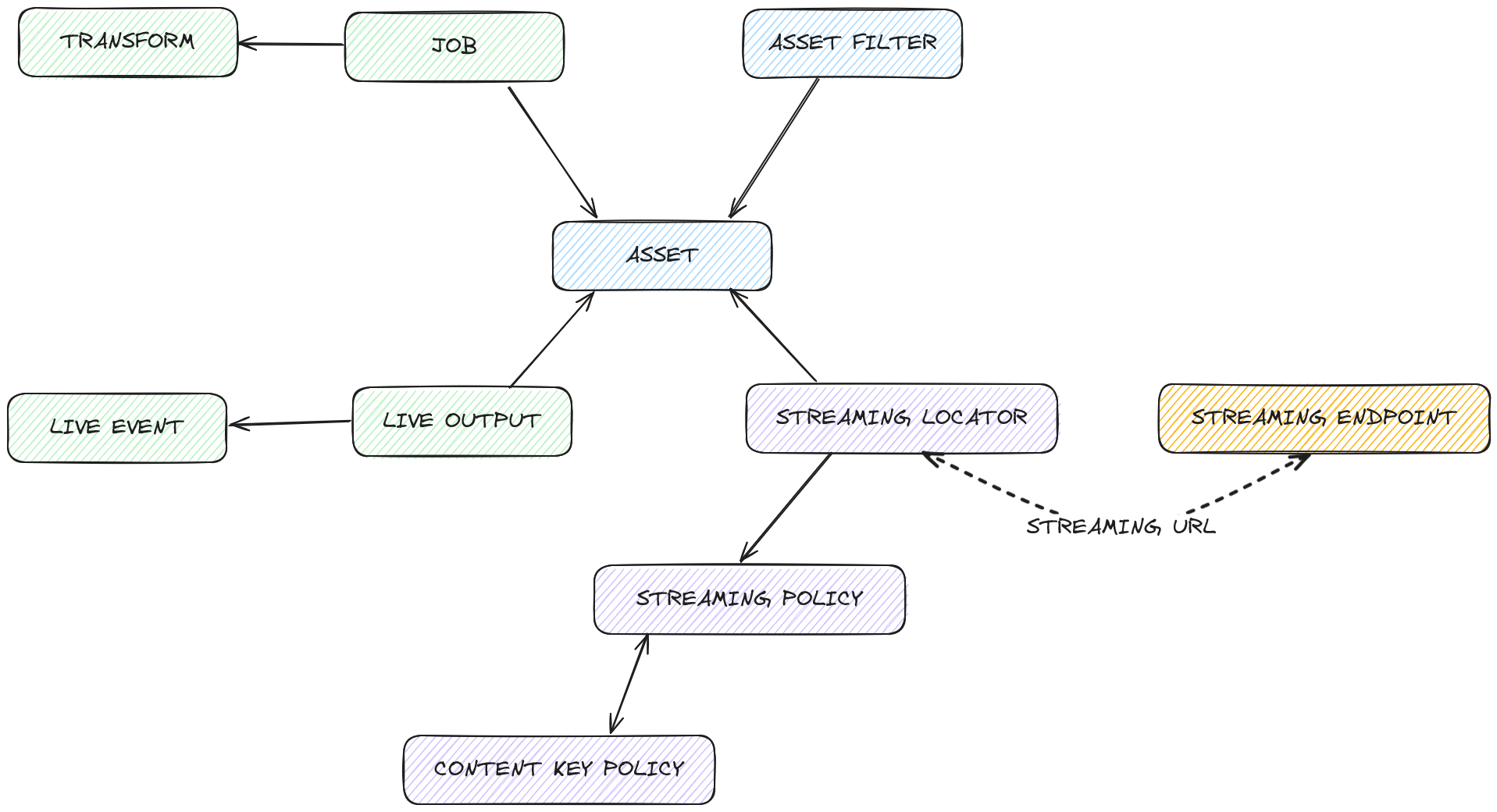
Data model
Assets then have policies attached to them via a Streaming Locator, which can then be bound to a Streaming Endpoint for delivery.
Let’s take a look at each of these in turn.
Updated about 1 month ago